YouTube Querier with Langchain and Gradio
Following up on my latest blog post on Langchain, in this short post I will show one of the possible ways to implement a YouTube Querier so that we can ask questions about a video with just natural language. The idea is pretty basic but effective and does not require a lot of code, thanks to the Langchain framework and the various models and packages I am going to use for this scenario.
What we need
Langchain to create embeddings (again OpenAI), create a vector store (Chroma) and interaction with it via LLM.
PyTube to download the audio of a video from YouTube.
Whisper from OpenAI to create transcriptions on the downloaded audio.
Gradio to easily create a chat UI.
Workflow
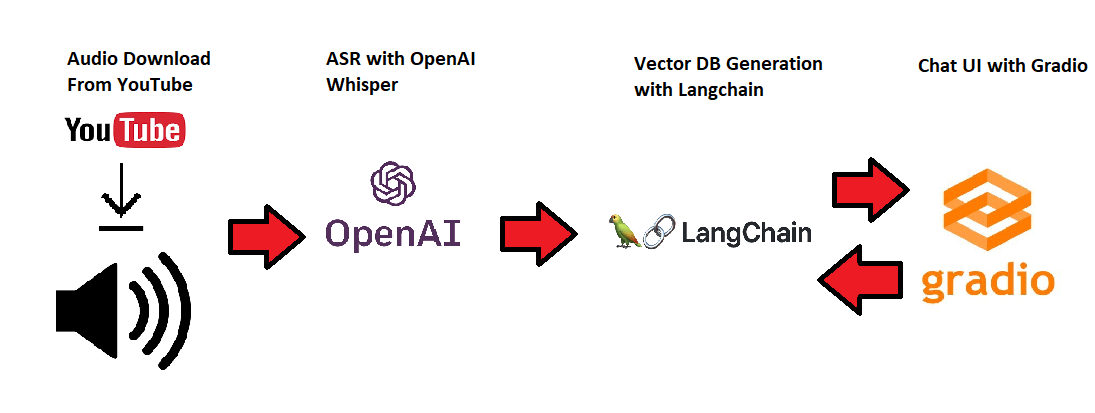
- Download audio from YouTube via PyTube.
- Pass the downloaded audio to Whisper
- Create from the segments returned from Whisper a corpus
- Split corpus into shorter texts with Langchain and create embeddings and save to vector store as a persist store so that we can read from the db any time and no need to recompute every time the embeddings etc.
- Create UI in Gradio where we will ask questions to the LLM about the video
Setup
We will have two main scripts for this. In one script we will take care of the audio downloading, transcription and vector db. In the second script we will have the Gradio Chat UI and use the vector db created with the first script.
Let’s get to work and download the audio, transcribe it and create the vector db.
PART I
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.chroma import Chroma
import whisper
import pytube
from datetime import timedelta
from typing import List, Tuple, Dict
PERSIST_DIR = "db"
WHISPER_MODEL_SIZE = "small"
whisper_model = whisper.load_model(WHISPER_MODEL_SIZE)
def organize_segments(segments) -> Tuple[List[str], List[str]]:
texts = []
start_times = []
for segment in segments:
text = segment["text"]
start = segment["start"]
start_timestamp = str(timedelta(seconds = start)).split(".")[0]
texts.append("".join(text))
start_times.append(start_timestamp)
return texts, start_times
def split_data(texts, start_times) -> Tuple[List[str], List[str]]:
text_splitter = CharacterTextSplitter(chunk_size=1024,
separator="\n",
chunk_overlap=64)
docs = []
metadatas = []
for i, d in enumerate(texts):
splits = text_splitter.split_text(d)
docs.extend(splits)
metadatas.extend([{"source": start_times[i]}] * len(splits))
return metadatas, docs
def transcribe(video: str) -> List:
transcription = whisper_model.transcribe(f"/pytube/content/{video}.mp4")
return transcription["segments"]
def create_vector_db(transcription: List[Dict]) -> None:
texts, start_times = organize_segments(transcription)
metadatas, docs = split_data(texts, start_times)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_texts(texts = docs,
embedding = embeddings,
persist_directory = PERSIST_DIR,
metadatas=metadatas)
vectordb.persist()
def download_videos(url) -> None:
video = pytube.YouTube(url, use_oauth=True, allow_oauth_cache=True)
video.streams.get_highest_resolution().filesize
audio = video.streams.get_audio_only()
audio.download(output_path="/pytube/content/",
filename= f"{video.title}.mp4")
whisper_transcription = transcribe(video.title)
create_vector_db(whisper_transcription)
print(f"Done, vector created for {video.title}")
if __name__ == "__main__":
download_videos("https://www.youtube.com/watch?v=f7jBigoHaUg")
The code should be self-explanatory but here below a few comments:
-
The small model is used for Whisper. Since the video in this snippet is a farily clear audio, there’s no need for larger model. Also faster to get the transcriptions back.
-
The pytube does not work without the use_oauth and allow_oauth_cache set. This drove me nuts for so many times and eventually found out I had to set those parameters else an exception is thrown.
-
For Vector DB I am using Chroma, same as in previous blog post. You could do the same with FAISS for example.
-
To make the vector db persist, define a folder where you will save the index and then remember to set the vectordb.persist()
PART II (The UI)
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
import gradio as gr
PERSIST_DIR = "db"
EMBEDDINGS = OpenAIEmbeddings()
db = Chroma(
persist_directory = PERSIST_DIR,
embedding_function = EMBEDDINGS
)
memory = ConversationBufferMemory(memory_key = "chat_history",
return_messages=False)
qa = ConversationalRetrievalChain.from_llm(
llm=OpenAI(temperature=0, max_tokens=-1),
chain_type="stuff",
retriever = db.as_retriever(),
get_chat_history = lambda h: h,
memory = memory,
verbose = True
)
with gr.Blocks() as demo:
chatbot = gr.Chatbot([], elem_id="YouTube Video Chatbot").style(height=750)
def add_text(history, text):
history = history + [(text, None)]
return history, gr.update(value="", interactive=False)
def bot(history):
response = qa.run({"question" : history[-1][0], "chat_history" : history[:-1]})
history[-1][1] = response
return history
with gr.Row():
with gr.Column():
chat_txt = gr.Textbox(
show_label=False,
placeholder="Ask your question",
).style(container=False)
txt_msg = chat_txt.submit(add_text, [chatbot, chat_txt], [chatbot, chat_txt], queue=False).then(
bot, chatbot, chatbot
)
txt_msg.then(lambda: gr.update(interactive=True), None, [chat_txt], queue=False)
demo.launch(debug=True, enable_queue=True)
A few comments in here:
-
We use the ConversationalRetrievalChain and ConversationBufferMemory from Langchain so that we can have that chat workflow we are looking for.
-
In the ConversationRetrievalChain we pass OpenAI as LLM (could set others too if you wanted to), as retriever it is the vector db we created earlier.
-
The code for the UI was simply taken from the Gradio webpage but slightly modified.
-
In the function “bot” we basicalaly pass the question and history of the chat to the LLM, in this case named qa
Chatbot in Action
Fire up the gradio app and open it in the browser. The UI is very simple, just type your question about the video and wait for the answer from the bot, it is very quick in doing that.
The video in question was about AI News of the week (last week from the time of this blog post). Some of the topics were NVIDIA Neuralangelo, RealityGPT, etc.
CHAT EXAMPLES
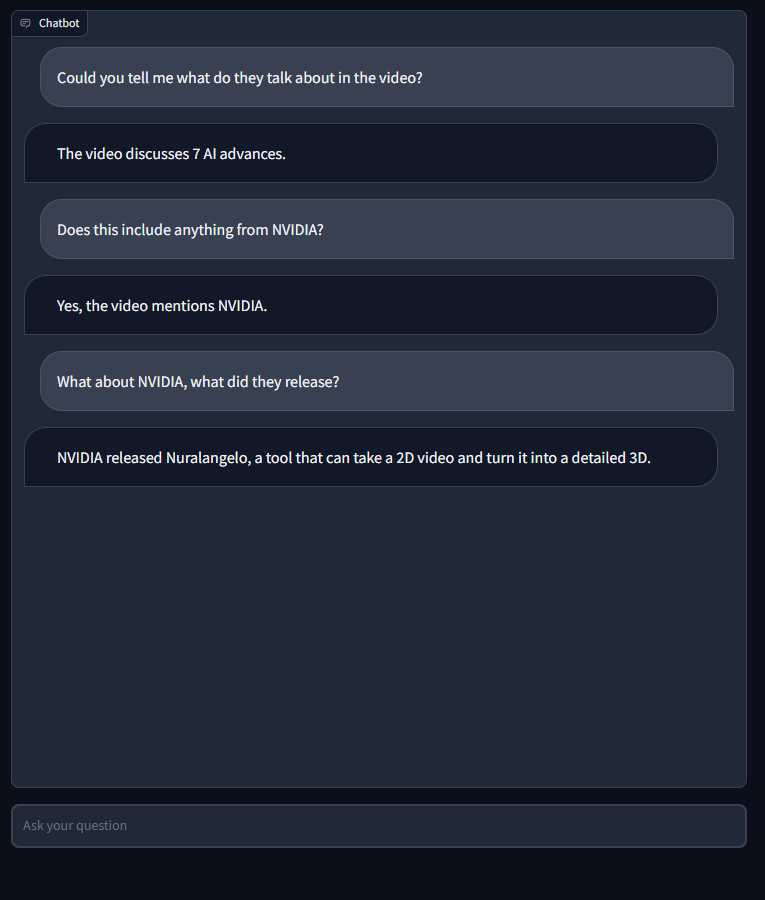
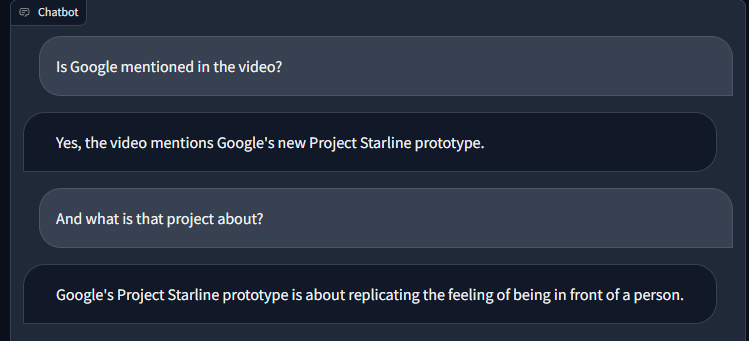
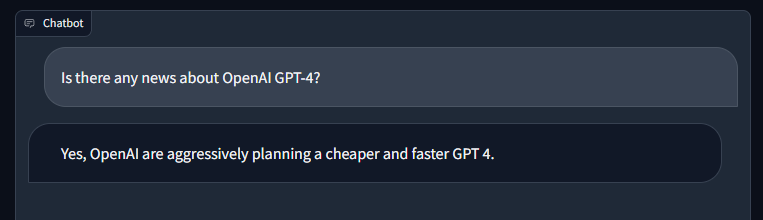
If you watch the video, the replies from the bot are correct. Of course, in some cases the bot would reply “I don’t know” which was unexpected. Also, the replies are not really that extensive. Moreover, when asked to describe with max 7 sentences what it’s discussed in the video, the reply was simply made-up, even though the temperature is set to 0:
The video discusses seven AI advances that may have been missed in the past week. These advances include the development of AI-powered robots that can perform complex tasks, the use of AI to improve medical diagnosis accuracy, the use of AI to improve facial recognition accuracy, the use of AI to improve natural language processing, the use of AI to improve autonomous vehicle navigation, the use of AI to improve image recognition accuracy, and the use of AI to improve machine learning algorithms.
Maybe the transcription was not that succesfull or maybe a different splitting would help? ¯\_(ツ)_/¯