Langchain and Streamlit
Langchain is probably the hottest framework right now if you are interested in building LLMs powered apps. So I thought, why not trying it out and combine it with some UI like Streamlit. There is quite a lot you can accomplish with Langchain.
Use Cases
For this blog post I wanted to focus on two use cases. ChatGPT and all the other available LLMs that are mushrooming almost on a daily basis do not really have access to the web, so as in the case of ChatGPT, there is a cut off date of September 2021. This means that anything that happened after that, ChatGPT does not really have knowledge of. There will be plug-ins available for ChatGPT that will allow it to access data from the internet but for now it is not really possible. Moreover, say you are a company that has some internal documentation, lots of it, and you want to be able to interact with the information in the documentation, without scanning through it, wouldn’t it be cool to be able to have a ChatGPT-look-alike UI where you can ask about the documentation? Well, with Langchain you can create such thing, a customized GPT.
But that’s not all. Langchain has so many features that it would be difficult to cover them all in a single post. However, one thing that I wanted to try out besides a customized GPT, was to be able to interact with data, with Excel data. If you like me work with data, manipulating and extracting insights with either pandas or polars, interacting with tabular data should not be a problem. However, in Langchain there are Agents, a series of them, that have specific skills. One of the available agents is called “create_csv_agent”. This agent, based on the documentation lets you interact with a CSV. Under the hood this agent calls the Pandas DataFrame agent to do the data manipulation needed to reply to your query. It is actually pretty neat and lets people without deep knowledge of Excel or data manipulation to extract valuable insights with just natural language. So let’s dive in.
CSV AGENT
The Streamlit app is very simple and has on the left side panel the options to interact either with the CSV Agent or the custom GPT.
To run a query on a CSV is actually very simple and does not require that many lines of code. One thing to note is that you will need to have the OpenAI API Key in your environment variables, else this will not work.
All you have to do, once you load the Excel in memory, is to pass the file to the agent, set the temperature (preferably to 0 so it does not make up information, although I will show you that in one case it gave an absurd answer despite the temperature set to 0) and the verbose to either True, if you want to see the whole agent’s chain of thoughts in the terminal, or False if you do not.
Here is a snapshot of the code to do that.
uploaded_file = st.file_uploader("Upload an Excel file")
if uploaded_file is not None:
if uploaded_file.name.endswith(".xlsx"):
df = pd.read_excel(uploaded_file)
elif uploaded_file.name.endswith(".csv"):
df = pd.read_csv(uploaded_file)
st.write(df)
agent = create_csv_agent(OpenAI(temperature=0),
uploaded_file.name,
verbose = True)
question = st.text_area("Type your question here", height = 100)
# Display the user's question
if question:
bot_out = agent.run(question)
st.write(bot_out)
For this demo, I took a taxi dataset from Kaggle from here
See the CSV Agent in action
In the terminal it is possible to follow what the agent is thinking to do, what actions and what pandas commands are being used, pretty cool stuff.
In case it is not too clear from the video, this is what was asked to the agent to do:
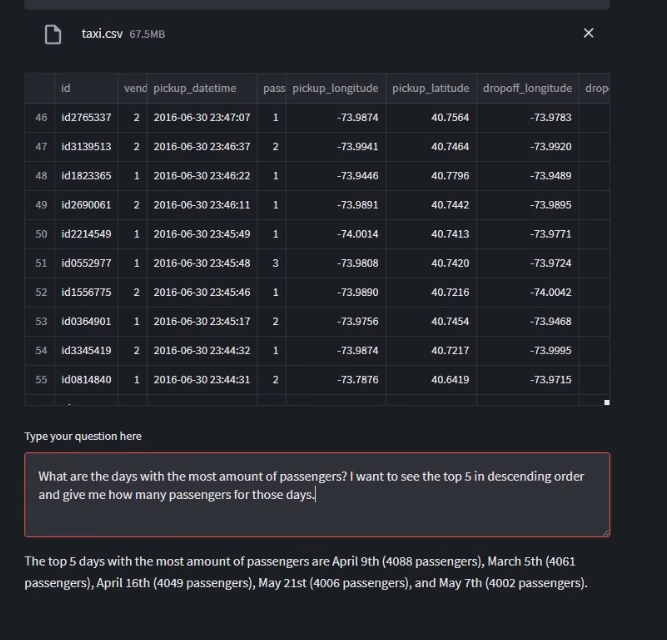
Now, one thing that is important to note is that, if the prompt you give is not well structured, you may get a wrong answer. I could verify the answers myself but in some case I could see that something was wrong. For example, when asked “what was the longest trip done”, if you look at the dataset, the only information about distances are longitude and latitude of pick-up and drop-off. To calculate the distance you would need to use a package such as geopy. In some cases the agent was trying to install geopy and run the right commands but it was always encoutering the same mistake and could not solve the problem. In one instance though, when prompted this question, the agent started to mention about a column named “Distance” in the dataframe that could have been used to calculate the distance. The column does not exist so not sure what was going on…hallucinations? :)
Custom GPT
In my previous blog post I wrote about UNET and SAM from Meta. SAM was released only a few weeks ago and if you ask ChatGPT what is SAM, this is what you get in return.
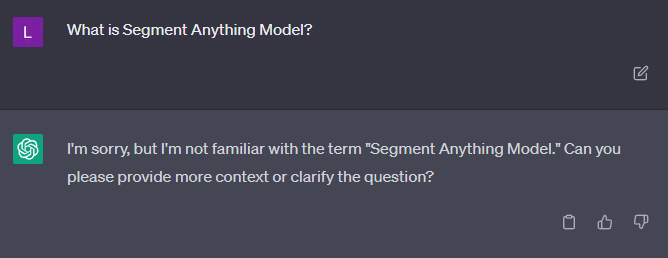
This is expected since the data is only until Sept 2021. For this demo, I took the paper for SAM.
There are different ways of doing this but for this demo I used the Chroma.from_documents method. It would be better to save it as a db so that it is persistent.
The txt data you first pass it to the TextLoader available from the langchain.document_loaders. Then you chunk the text and decide the size of the chunks. In this case we use the OpenAIEmbeddings and since we want to have a conversation with the bot, we will use the ConversationalRetrievalChain. One thing to note from the parameters passed to the chain is the “retriever = vectorstore.as_retriever(),” The vectorstore in this case is the document passed to Chroma.
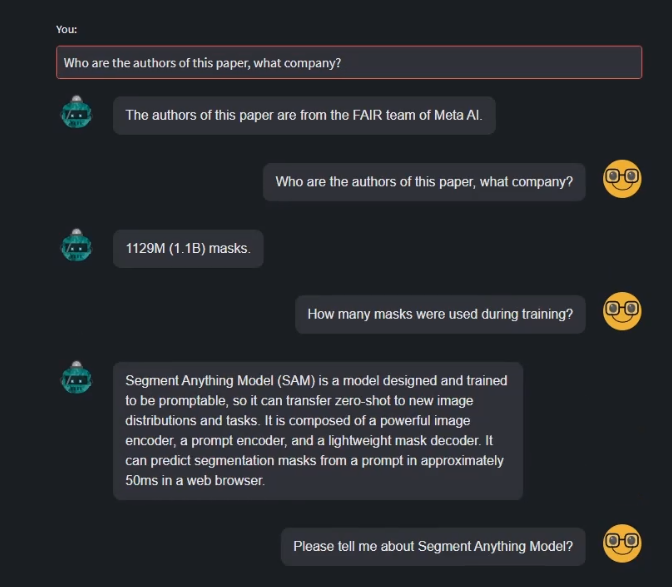
Ask about SAM to the customized GPT
This agent is able to retrieve information from the document and knows what is SAM and details about it, so it seems like it is working fine. This same method can be applied to different scenarios, like having an interactive Q&A, especially when having a multitude of different documents. Below is the whole code.
In case the video is not too clear, here is a screenshot of the interaction
Full Code
import streamlit as st
from streamlit_chat import message
import pandas as pd
from langchain.llms import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.agents import create_csv_agent
options = ["Ask Excel", "Chat"]
selected_option = st.sidebar.selectbox("Select an option", options)
def chat_tab():
def load_bot() -> ConversationalRetrievalChain:
"""Load bot"""
loader = TextLoader("data/sam_scraped.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=0,
separator="\n")
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
memory = ConversationBufferMemory(memory_key = "chat_history",
return_messages = False)
bot = ConversationalRetrievalChain.from_llm(
llm = OpenAI(temperature=0),
chain_type = "stuff",
retriever = vectorstore.as_retriever(),
memory = memory,
get_chat_history = lambda h: h,
verbose = True
)
return bot
chain = load_bot()
if "generated" not in st.session_state:
st.session_state["generated"] = []
if "past" not in st.session_state:
st.session_state["past"] = []
def get_text():
input_text = st.text_input("You: ", "Hi, I am Loris.", key="input")
return input_text
user_input = get_text()
if user_input:
output = chain.run({"question" : user_input})
st.session_state.past.append(user_input)
st.session_state.generated.append(output)
if st.session_state["generated"]:
for i in range(len(st.session_state["generated"]) - 1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state["past"][i], is_user=True, key=str(i) + "_user")
# Define the contents of the "Ask Excel" tab
def ask_excel_tab():
st.write("Ask me questions on your Excel")
uploaded_file = st.file_uploader("Upload an Excel file")
if uploaded_file is not None:
if uploaded_file.name.endswith(".xlsx"):
df = pd.read_excel(uploaded_file)
elif uploaded_file.name.endswith(".csv"):
df = pd.read_csv(uploaded_file)
st.write(df)
agent = create_csv_agent(OpenAI(temperature=0),
uploaded_file.name,
verbose = True)
question = st.text_area("Type your question here", height = 100)
# Display the user's question
if question:
bot_out = agent.run(question)
st.write(bot_out)
option_tab_mapping = {
"Chat": chat_tab,
"Ask Excel": ask_excel_tab
}
if selected_option:
tab_func = option_tab_mapping[selected_option]
tab_func()