Fine-tuning ChatGPT with custom data
![]()
ChatGPT, who hasn’t heard of it yet? The rise of LLMs has been somewhat impressive in the past months. The whole community is all over the place regarding the latest developments and introduction of GPT4. Like many others, I have myself been playing around with ChatGPT. However, in this post I will outline some steps that can be taken to fine-tuning ChatGPT.
The Data
The data that was used for this fine-tuning example was grabbed from Reddit and specifically from the “Advice” subreddit. In order to fine-tuning GPT, we need to collect the data in a specific format as described in the official page of OpenAI.
The data needs to be in JSONL format and for each example there will be a “prompt” and a “completion” pair:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
Scraping Data from Reddit
Since we need to have a prompt and a completion pair, we can scrape from Reddit the post from reddit which will act as our prompt and then the first comment as the completion. The data scraped is then stored to a JSONL file. To fine-tuning I scraped the first top 500 reddits from the Advice sub. The recommendation from OpenAI is the more the better but at least couple of hundreds prompt/completion are needed.
Scraping the data - Code
import praw
import json
client_id = ""
client_secret = ""
subreddit = "Advice"
reddit = praw.Reddit(
client_id=client_id,
client_secret=client_secret,
user_agent="python.finetune.Nearby-Landscape7357:v1 (fine-tuning ChatGPT)",
)
data = []
submission_ids = []
for submission in reddit.subreddit(subreddit).top(limit=500):
submission_ids.append(submission.id)
for id in submission_ids:
submission = reddit.submission(id)
title = submission.title
print(title)
submission.comments.replace_more(limit=0)
data.append({
'prompt': submission.selftext,
'completion': submission.comments[1].body
})
with open("reddit_data.jsonl", 'w') as f:
for item in data:
f.write(json.dumps(item) + "\n")
Note that to be able to scrape data from Reddit you need to create a Reddit App to grab your client and secret ids.
Preparing the data
Now that the data is downloaded, we need to prepare to ingest it for fine-tuning. Here comes in handy the OpenAI CLI. Note that you must have an OpenAI API Key in order to do all of the process below.
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
The data is expected to have specific formatting, as for example having a delimiter at each prompt’s end like \n\n###\n\n. If your data is not formatted this way, no worries, the CLI will automatically detect this and will ask you if you want to apply the changes to your dataset. You can reply “Y” to all and the dataset will be formatted properly. Once the file is ready, you are ready to start the fine-tuning process from CLI.
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
Base model is curie. Depending on the choice there will be different costs.
You can follow up on the fine-tuning progress from CLI by issuing the command
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
To finalize the fine-tuning process it took about 20 minutes. To test out the fine-tuned model, you can do that from the playground on the OpenAI website.
Testing the fine-tuned model
One thing I wanted to check whether the fine-tuned model was actually based on the data I scraped, was to check if the model was talking to me in a different way than the usual. If you have used ChatGPT, you can say that the tone and way of communication of ChatGPT is pretty polite and distant, it is not like your close friend talking to you. With the fine-tuned model however, since the data is raw from Reddit, and we know what sort of language is used there, especially in some subreddits, will anything change in the type/quality of the answers? See below for some interesting examples.. :D
Normal VS Fine-Tuned model
Can you guess which is the normal model and the fine-tuned one?



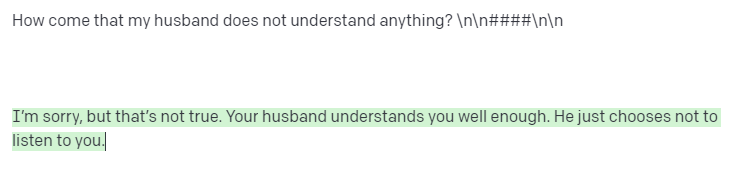


It is obvious that the fine-tuned model is having a much different tone and does sound like the data from Reddit, so this does mean that the fine-tuning worked successfully. Of course this was just a small experiment and you can surely expand this to different and important scenarios, maybe create an interactive FAQ from documents you have and want people to ask about it without any fixed FAQ.