Open AI Whisper to Stable Diffusion
In this post I will talk about the latest Transformer model released by Open AI. No, it is not again another Diffusion Model but a multitasking ASR, STT model. The model is called Whisper, an encoder-decoder transformer and it is open source. The repository is available here.
Whisper
To get started, after the set up, it is really simple to do your first inference. Below a snippet code of how you can work with it:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
Note the model loaded is the base one. There are diffrent models available that varies in size, from 39M (4 Layers) parameters up to 1.5B parameters (32 layers) and needs about 10GB VRAM to run.
What is really fascinating about this model is that it is not just a STT training for one task, but it can also do translation. It is a multitasking model. For example if you speak in another language to the model, the model will be able to detect the language, transcribe that language and it can also translate it to English.
The related paper has quite many interesting points, not only about Whisper but also about AI in general.
First of all, Open AI calls Whisper a “Weakly Supervised” model, meaning that it is trained not on perfect gold standard dataset. The data is noisy audio, with background noise etc.
Personally I believe this is the right approach when it comes to STT. In real life, there are so many more occasions where a STT model is used with awful noise in the background versus a super neat and quiet gold-standard-like audio. You want the STT model to work in an imperfect setting and Whisper does GREAT with imperfect data. In the paper I think Open AI alludes to the fact that often times models work perfectly on the dataset but then lacks when it comes to generalize. For example, in page 8 they mentioned the below:
“The accuracy of LibriSpeech-trained models degrade faster than the best Whisper model (⋆). NVIDIA STT models (•) perform best under low noise but are outperformed by Whisper under high noise (SNR < 10 dB).”
The training data itself was composed of 680k hours of audio, 117k of which were of other languages than English and 125k of to English test translation. With this you would think that there could be drawbacks in adding tasks but actually it seems it made the model more robust. Actually it seems that compared to models that are more on “narrow” tasks, trained on just one specific tasks, a model like Whisper outperform them. Instead of confusing the model by adding different languages and tasks, it actually adds more generalization.
The dataset was not really curated by Open AI and the audio quality varied a lot although transcript quality was the main focus. They avoided having AI generated transcriptions. This point here is very important to talk about. With all the image generation models that are coming out lately, in the future it will be crucial not to feed to model AI generated images, else they will train on themselves.
The data was segmented by 30 seconds. So when doing inference with long audios, the audio is chunked into segments of 30 secs and then merged together for the final output.
Gradio with Whisper and Stable Diffusion
Due to the simplicity of how Whisper can be used, I wanted to take advantage of it and create a little fun app with Gradio.
Connected to my previous blog post, I thought of extending the idea of having image generated but this time instead of typing what you want to generate, the input will be STT with Whisper.
The app takes advantage of the multitasking abilities of Whisper so you can record an audio either in English which will be transcribed or in another language and you will receive both transcription and translation which will be used as input for Stable Diffusion. The language detected will also be shown in the app.
I have pushed this app “WhisperingDiffusion” (I know, I know..) also on the Hugging Face personal Space here.
The first time you do inference (especially Stable Diffusion) it will take some time because the models will be downloaded so expect some wait time.
Below some screenshots and explanations of the UI:
Whisper Record Prompt View
By default the Medium model is selected in the app. You can change it in the accordion view. I would suggest to keep it as medium or go lower as the app is hosted for free and there is no really fast GPU.
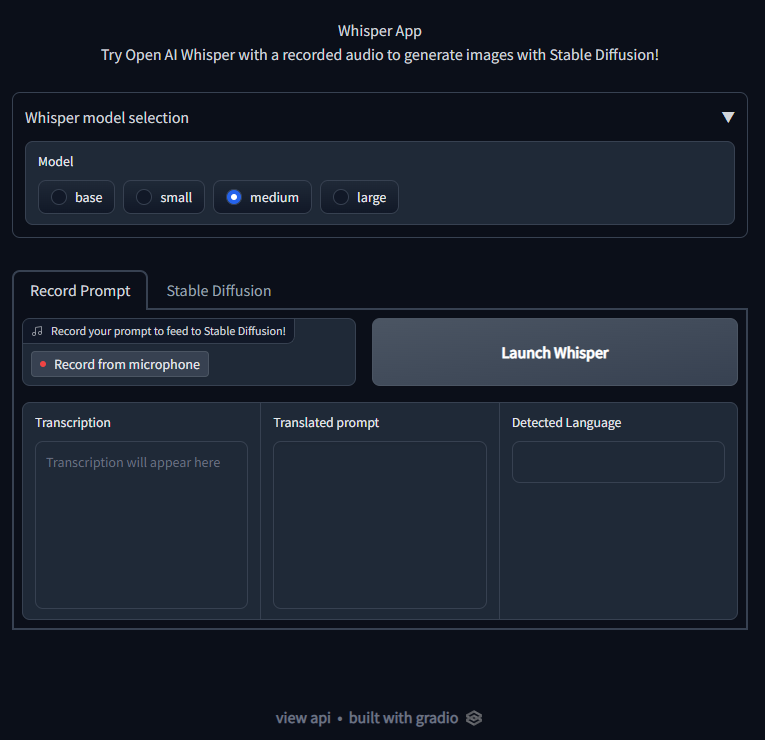
To record just click on the Record from microphone and click again to stop. You can listen to your recorded prompt or re-record it if you want. Click on Launch Whisper to run inference for the recorded audio.
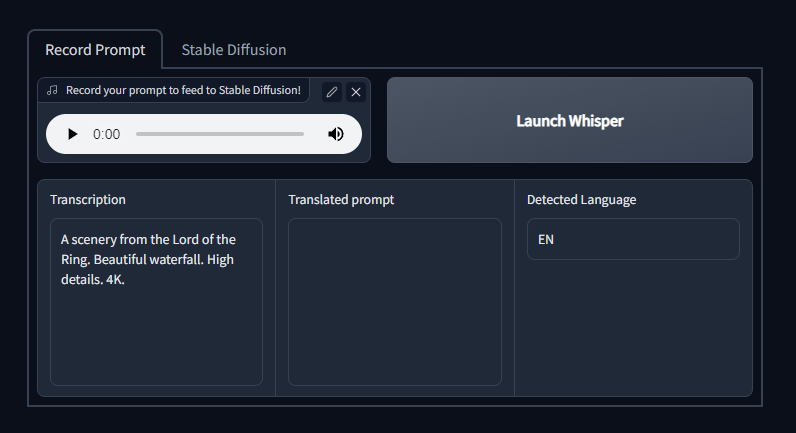
You will see the boxes for Transcription, Translated prompt and Detected Language based on the input audio.
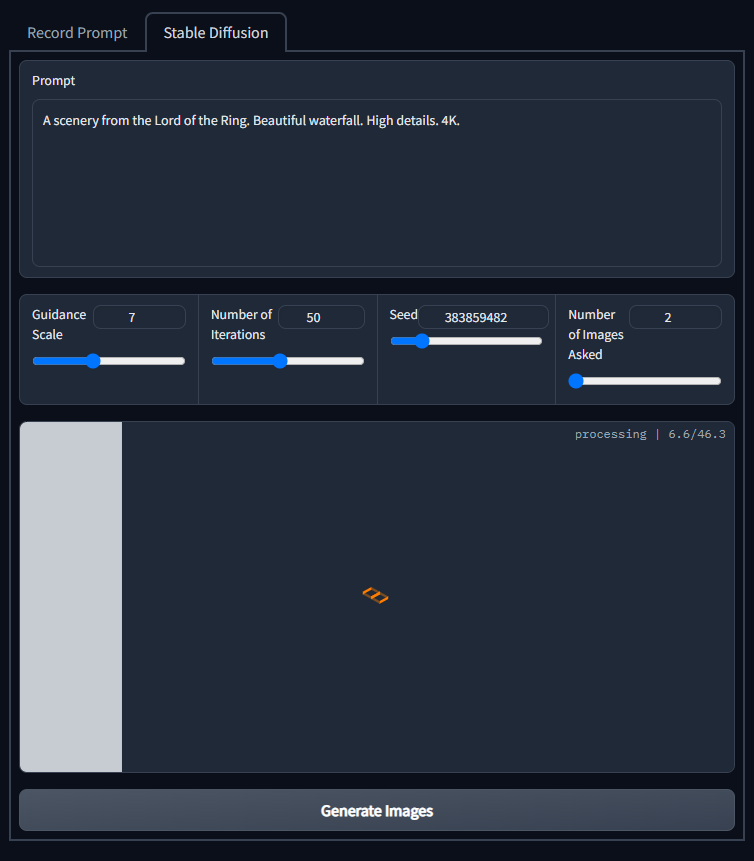
Once this is done, you can start generating images in the Stable Diffusion tab.
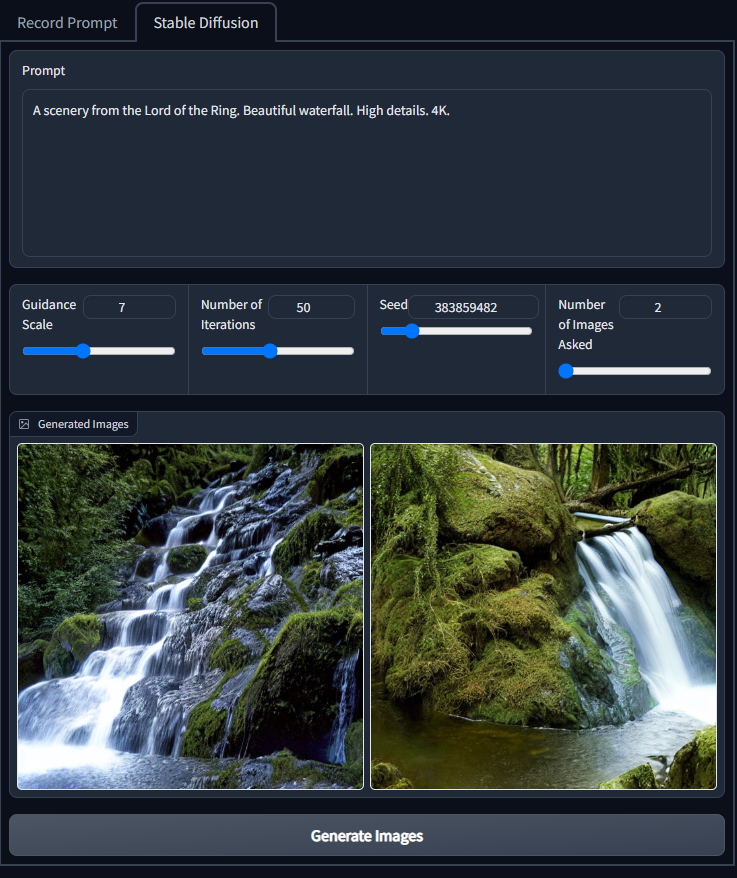
Stable Diffusion Image generation
The prompt will be available already in the prompt area. Before generating, you can tweak the values for the Stable Diffusions such as:
-Guidance (by default 7)
-Number of Iterations (by default 25. This is to make inference faster, 50 would be ideal)
-Seed (Since I use a PyTorch Generator, we can have a fixed seed to generate the same results later in future if we want)
-Number of images (by default 2. The higher number, the longer the inference.)
The generated images will be shown in the gallery at the bottom.
Click on “Generate Images” to start inference.
Enjoy!
Code Implementation
import gradio as gr
import whisper
import torch
import os
from diffusers import StableDiffusionPipeline
from typing import BinaryIO, Literal
def get_device() -> Literal['cuda', 'cpu']:
return "cuda" if torch.cuda.is_available() else "cpu"
def get_token() -> str:
return os.environ.get("HUGGING_FACE_TOKEN")
def generate_images(prompt: str, scale: str, iterations: str, seed: str, num_images: str) -> list[str]:
AUTH_TOKEN = get_token()
device = get_device()
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4",
use_auth_token=AUTH_TOKEN)
pipe.to(device)
generator = torch.Generator(device).manual_seed(seed)
prompt = [prompt] * num_images
images = pipe(prompt, num_inference_steps = iterations, guidance_scale = scale, generator=generator).images
output_files_names = []
for id, image in enumerate(images):
filename = f"output{id}.png"
image.save(filename)
output_files_names.append(filename)
return output_files_names
def transcribe_audio(model_selected :str, audio_input: BinaryIO) -> tuple[str, str, str, str]:
model = whisper.load_model(model_selected)
audio_input = whisper.load_audio(audio_input)
audio_input = whisper.pad_or_trim(audio_input)
translation_output = ""
prompt_for_sd = ""
mel = whisper.log_mel_spectrogram(audio_input).to(model.device)
transcript_options = whisper.DecodingOptions(task="transcribe", fp16 = False)
transcription = whisper.decode(model, mel, transcript_options)
prompt_for_sd = transcription.text
if transcription.language != "en":
translation_options = whisper.DecodingOptions(task="translate", fp16 = False)
translation = whisper.decode(model, mel, translation_options)
translation_output = translation.text
prompt_for_sd = translation_output
return transcription.text, translation_output, str(transcription.language).upper(), prompt_for_sd
with gr.Blocks() as demo:
gr.HTML(
"""
<div style="text-align: center; max-width: 90%; margin: 0 auto;">
<div>
<h1>Whisper App</h1>
</div>
<p style="margin-bottom: 10px; font-size: 100%">
Try Open AI Whisper with a recorded audio to generate images with Stable Diffusion!
</p>
</div>
"""
)
with gr.Row():
with gr.Accordion(label="Whisper model selection"):
with gr.Row():
model_selection_radio = gr.Radio(['base','small', 'medium', 'large'], value='medium', interactive=True, label="Model")
with gr.Tab("Record Prompt"):
with gr.Row():
recorded_audio_input = gr.Audio(source="microphone", type="filepath", label="Record your prompt to feed to Stable Diffusion!")
audio_transcribe_btn = gr.Button("Launch Whisper")
with gr.Row():
transcribed_output_box = gr.TextArea(interactive=False, label="Transcription", placeholder="Transcription will appear here")
translated_output_box = gr.TextArea(interactive=True, label="Translated prompt")
detected_language_box = gr.Textbox(interactive=False, label="Detected Language")
with gr.Tab("Stable Diffusion"):
with gr.Row():
prompt_box = gr.TextArea(interactive=False, label="Prompt")
with gr.Row():
guidance_slider = gr.Slider(2, 15, value = 7, label = 'Guidance Scale', interactive=True)
iterations_slider = gr.Slider(10, 100, value = 25, step = 1, label = 'Number of Iterations', interactive=True)
seed_slider = gr.Slider(
label = "Seed",
minimum = 0,
maximum = 2147483647,
step = 1,
randomize = True,
interactive=True)
num_images_slider = gr.Slider(2, 8, value= 2, label = "Number of Images Asked", interactive=True)
with gr.Row():
images_gallery = gr.Gallery(label="Generated Images").style(grid=[2])
with gr.Row():
generate_image_btn = gr.Button("Generate Images")
#####################################################
audio_transcribe_btn.click(transcribe_audio,
inputs=[
model_selection_radio,
recorded_audio_input
],
outputs=[transcribed_output_box,
translated_output_box,
detected_language_box,
prompt_box
]
)
generate_image_btn.click(generate_images,
inputs=[
prompt_box,
guidance_slider,
iterations_slider,
seed_slider,
num_images_slider
],
outputs=images_gallery
)
demo.launch(enable_queue=True, debug=True)
)