Diffusers and Gradio
In my previous post I talked about using the original Stable Diffusion repo locally and how to run it from cmd line. This past weekend I wanted to explore more solutions on how to interact with Stable Diffusion and looked into Hugging Face’s Diffusers. Now, if you have never used HF before, I do recommend having a look at what they can offer. What you are able to do in very few lines of code is mind-blowing.
Diffusers by HF offer SOTA diffusion pipelines. Pipelines are basically a way to do inference with a model by just writing few lines of codes. It is really that simple. The output, as we know, are going to be images and I wanted to have a way to replace cmd prompt with something more user friendly. Here is where I ran into Gradio. Gradio allows you to build UI having in background ML models and more. A very cool feature of Gradio is that you can actually run the app and create a public link that is active for 72h, meaning people from anywhere can access your app via browser. This is very useful in case you want to showcase something online.
The plan
You can accomplish quite a lot with Gradio but the aim for this basic app was to have:
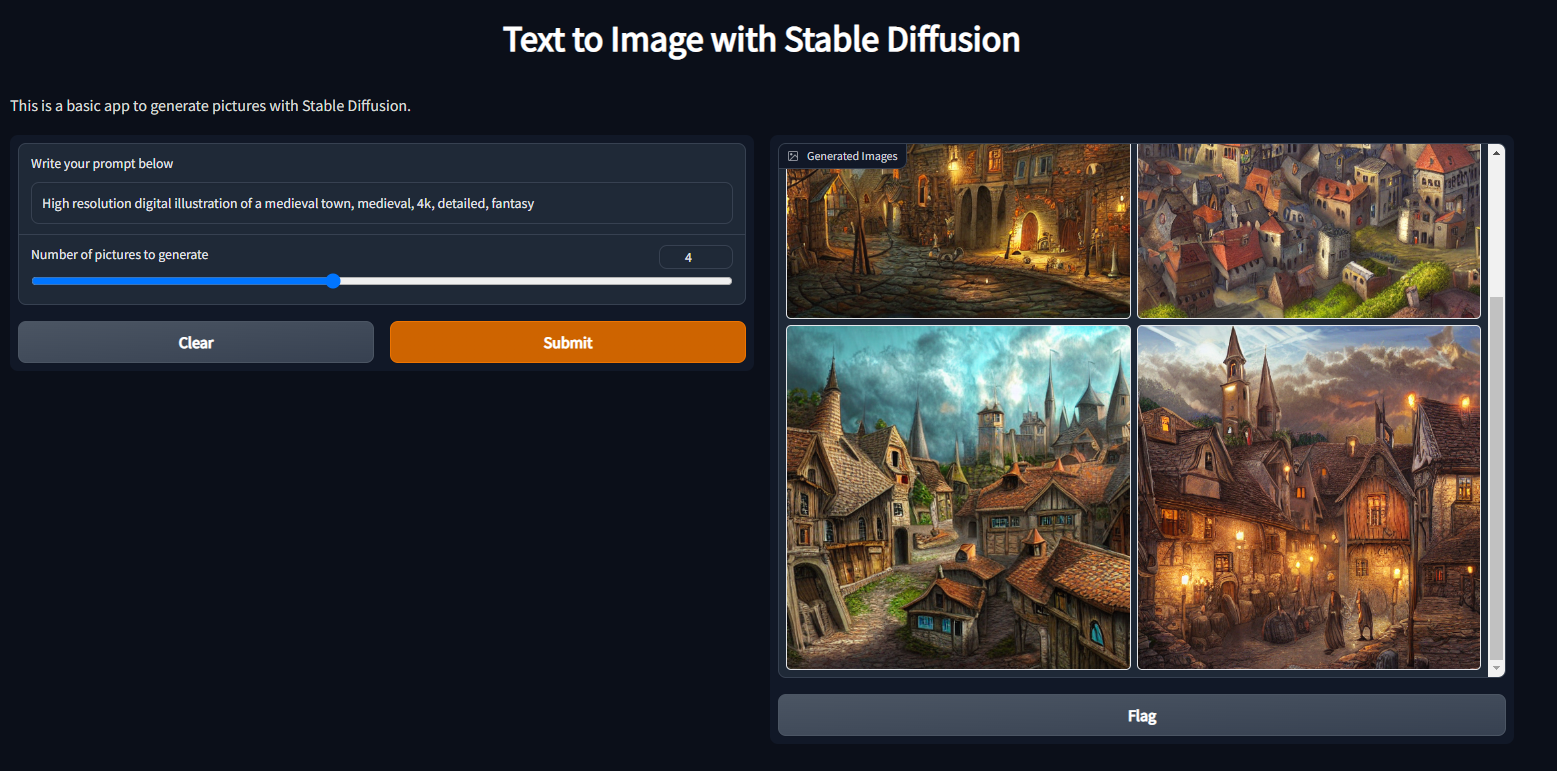
- Textbox to type the prompt to feed as input to the Stable Diffusion model.
- A slider to select the number of images you wanted in output for each inference for that particular prompt.
- A way to display the images created by Stable Diffusion.
Code implementation
Below you can see the code written for achieving what is listed above. A few notes:
- In order to use Stable Diffusion and the weights CompVis/stable-diffusion-v1-4 you need to accept the license on the HF website.
- Once you have accepted the terms, you will need to obtain an access token to be able to use the model within your code, hence the HUGGING_FACE_TOKEN taken from the environment variables. Never share your access tokens online :)
- When building the pipeline, if you do not have 10GB of GPU RAM available, then you can specify the revision to be fp16 (default is 32).
- For Gradio, at the beginning I was passing the images (PIL) to the Gallery component but you actually need to pass the paths of the generated images. Took me a while to figure it out.
- The number of pictures in output are based on the slider number selected. This value is passed in the create_img function. All it takes to tell the model to return (N) images is to have the prompt (coming from the textbox) as a list and muliplied by the number. “prompt = [prompt] * number_output_requested”
- Be default the app will be available on localhost but you can also specify share=True in the launch function and a public link will be generated active for 72h.
- If you do not have any GPU available, you can always run this on Google Colab!
import gradio as gr
import torch
from diffusers import StableDiffusionPipeline
import os
def get_token() -> str:
return os.environ.get("HUGGING_FACE_TOKEN")
def save_images(images: list) -> list:
output_files_names = []
for id, image in enumerate(images):
filename = f"output{id}.png"
image.save(filename)
output_files_names.append(filename)
return output_files_names
def create_img(prompt :str, number_output_requested: int) -> list:
AUTH_TOKEN = get_token()
generator = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=AUTH_TOKEN)
generator.to("cuda")
prompt = [prompt] * number_output_requested
with torch.autocast("cuda"):
images = generator(prompt).images
output_paths = save_images(images)
return output_paths
diffusers_app = gr.Interface(
fn=create_img,
inputs =
[
gr.Textbox(label="Write your prompt below", placeholder = "A squirrel bench pressing 200 kg"),
gr.Slider(value=1, minimum=1, maximum=8, step=1, label="Number of pictures to generate")
],
outputs = gr.Gallery(label="Generated Images").style(grid=[2]),
title="Text to Image with Stable Diffusion",
description="This is a basic app to generate pictures with Stable Diffusion."
)
diffusers_app.launch(debug=True)
The app
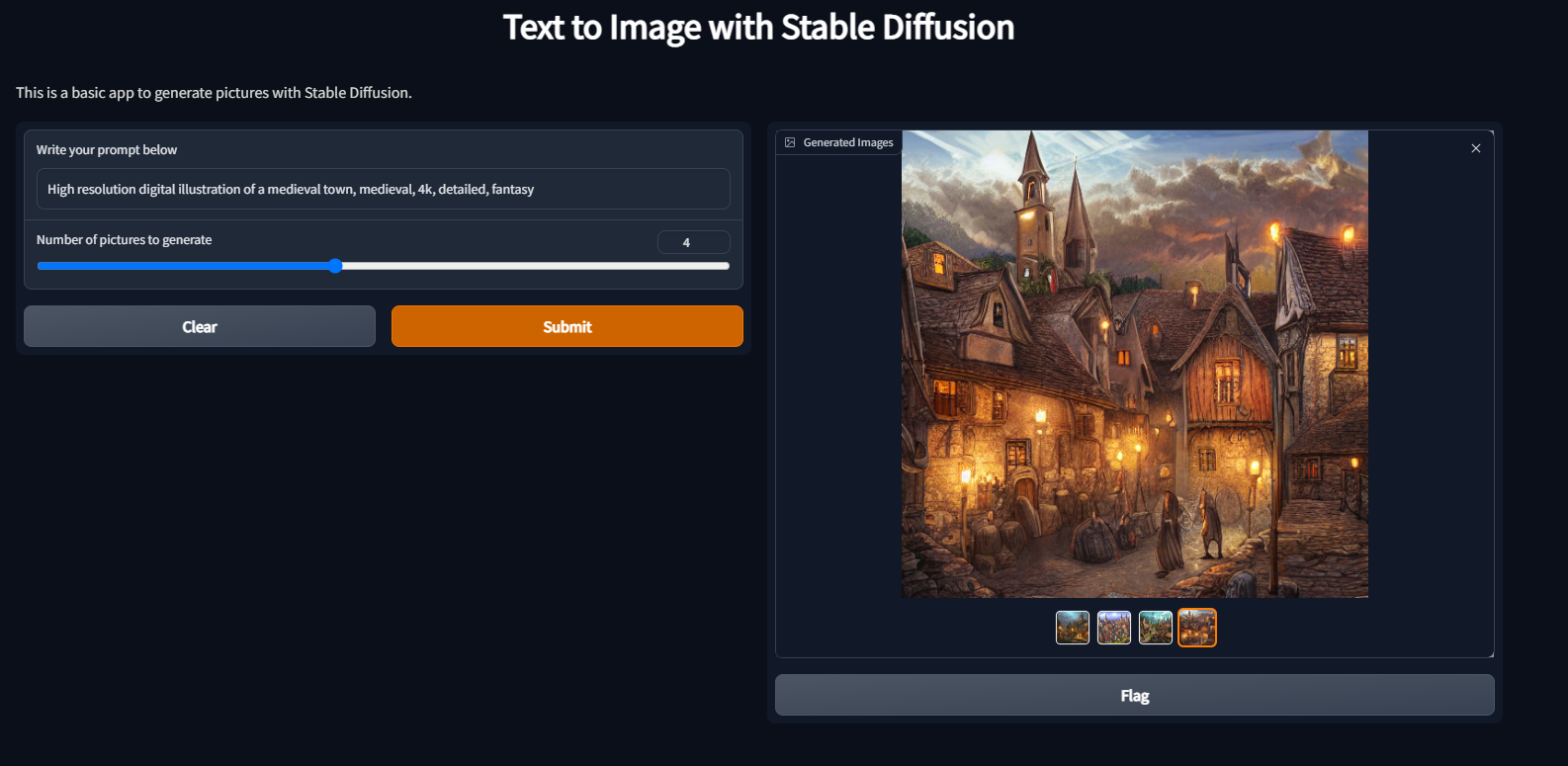
Main View
Inference Running
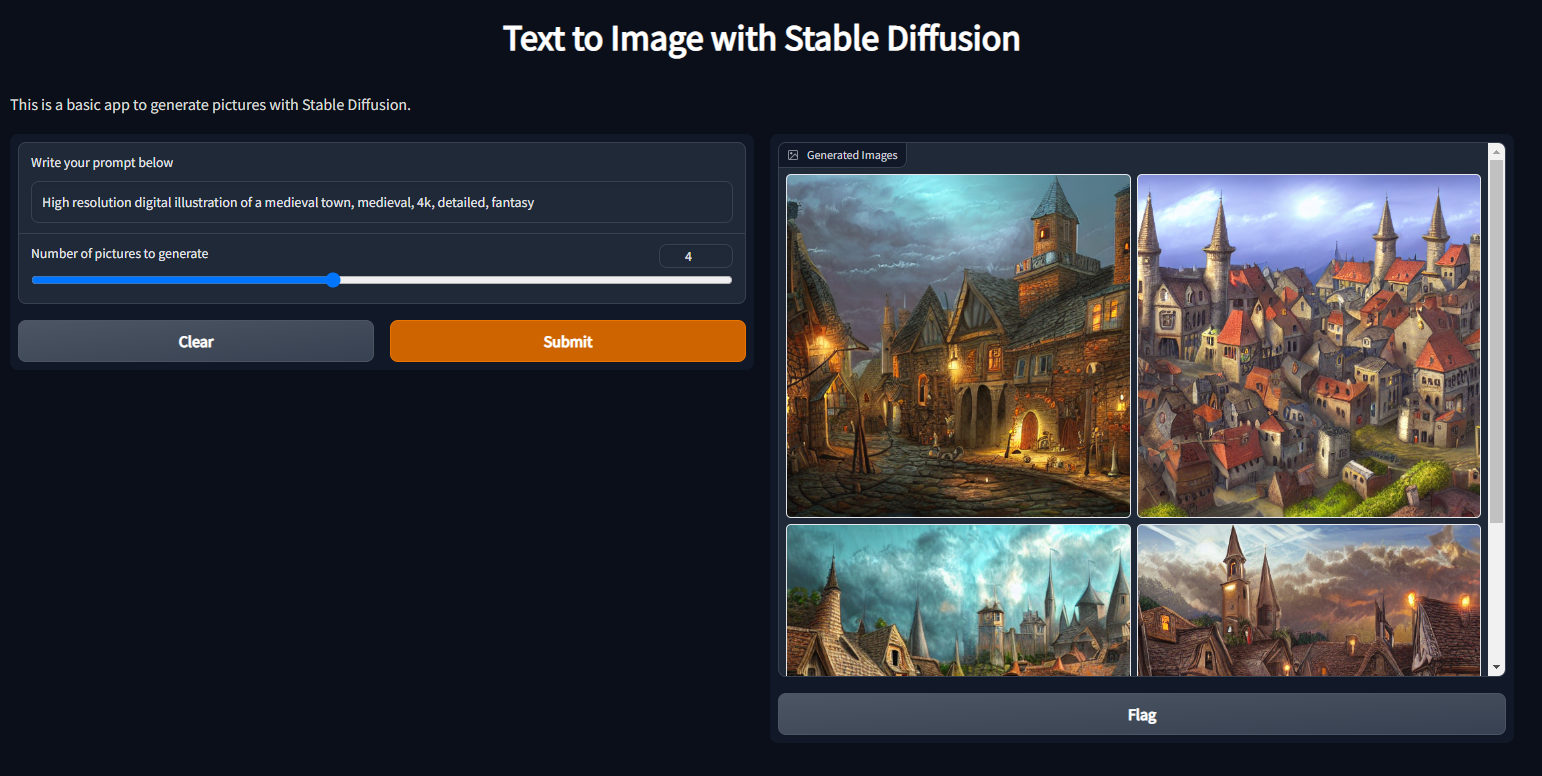
Outputs as a grid
Output as single image